Guidelines
Publication Guidelines
Publishing data on an open data portal involves a collaborative multi-step process (see Figure 3: Guidance Summary). In identifying publishable data, partnering organizations should include analyses from their executive and program staff, data coordinators, PRA officers, data stewards, IT, public information officers, security and privacy officers, and legal counsel.
Open data portal publishing contributors vary widely in terms of size, available personnel, functions, responsibilities, mission, and data collected and maintained. As such, the identification and prioritization processes may vary across entities. These guidelines serve to provide assistance across a broad spectrum of publishing contributors, with the stipulation that organizations look to their governing laws, rules, regulations, and policies in identifying and making available publishable data.
There are four main steps in the process of publishing data on an open data portal. These include:
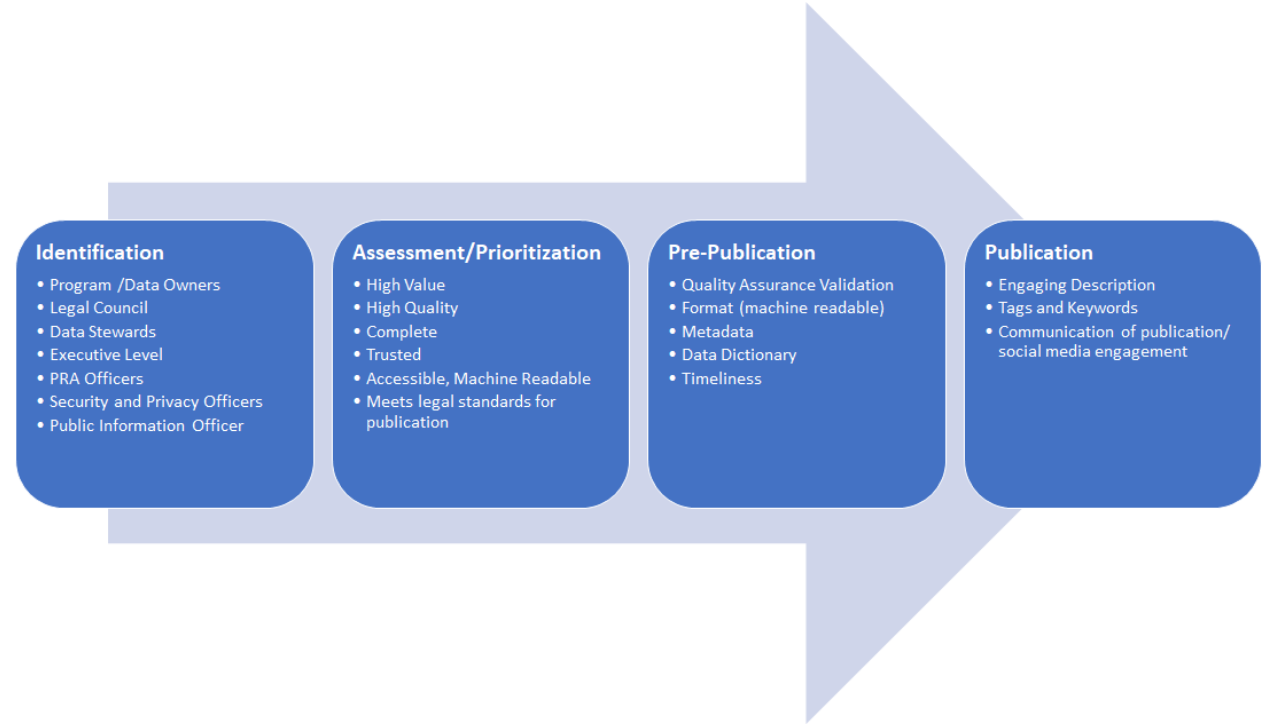
Figure 3: Guidance Summary
Four Steps of the Publishing Process
1. Data Identification and Inventory Template
Within a publishing contributor’s organization, any number of individuals can and should consider identifying themselves as stewards of potential open data tables. In addition, subject matter experts and leaders within the organization may also identify data that could fulfill strategic needs by sharing on the open data portal. After identification, all suggested data should be assessed and prioritized.
Data Inventory
Per SAM 5160.1 Item 4, Agencies/state entities should create and maintain an enterprise data inventory. This inventory should indicate whether datasets listed may be made publicly available (i.e., release is permitted by law, subject to all privacy, confidentiality, security, Agency/state entity has ownership of data, and other valid requirements) and whether they are currently available to the public. The inventory shall also list any datasets that can be made publicly available at the Agency/state entity’s open data site or portal in a format that enables automatic aggregation by Data.ca.gov and other services (known as “harvestable files”), to the extent practicable. Public data listing should include, to the extent permitted by law and existing terms and conditions, datasets that were produced as a result of legislative mandates, state grants, contracts, and cooperative agreements (excluding any data submitted primarily for the purpose of contract monitoring and administration). Where feasible, these listings should include standard citation information, including the data coordinator’s contact information and preferably using a persistent identifier.
The following are suggested fields to be captured with a data inventory:
- Title
- Description
- Data type
- Persistent Identifier
- If the file is non-machine readable (e.g., PDF), are the raw files that were used to compile the non-machine readable file available?
- If a file is stored in a database, what is the database type (e.g., SQL, SaaS, Oracle) ?
- Is this file housed within the organization?
- Is the file located in-house?
- Is the file hosted with the Department of Technology?
- Is the file hosted offsite?
- Comments
In addition, Data Coordinators for an organization and their contact information should be captured as well. The following are suggested fields to capture the Data Coordinator contact information:
- First Name
- Last Name
- Title
- Department
- Division
- Branch
- Section
- Unit
- Phone Number
- Types of data that the individual manages
- Comments
For an example of what a data inventory should include please see the link below. Please feel free to use this as a template for your organization’s data inventory.
Sample Data Inventory Template
2. Data Assessment/Prioritization
In creating a data catalog for an open data portal, publishing contributors should assess the suggested data for value, quality, completeness, and appropriateness in accordance with the definition of publishable state data. High value data are those that can be used to increase the contributor’s organizational accountability and responsiveness, improve public knowledge of the organization and its operations, further its mission, create economic opportunity, or respond to a need or demand identified through public consultation.
Sections A and B below are neither exhaustive nor applicable to all publishing contributors, but rather serve to provide a framework for identifying potential data for publication on an open data portal. For each question in Section A, organizations must assess whether the data fall within the definition of publishable state data and respective disclosure considerations.
Assessment Section A
General Questions to Identify High Value, High Priority Publishable Data
What “high value” data are currently publicly available?
Publishing contributors may already publish a considerable amount of data online, although it may not be necessarily accessible in bulk, or available through machine-readable mechanisms. Excellent starting points are reviewing weekly, monthly, or quarterly reports that are frequently accessed by the public, or reviewing public-facing applications that allow visitors to search for records.
What underlying data populate aggregate information in published reports?
Published reports are often populated with data which is compiled or aggregated from internal systems. For example, a weekly public report may indicate that an organization has closed 25 projects in that week. The internal system, which has details of each case, may have additional details which can be made public.
What data do organization programs use for trending and statistical analysis?
Similar to published reports, trend and statistical analysis is often performed using data from various sources. Those sources can be reviewed for data which can be made public.
What data is the subject of frequent PRA requests? What data is the public or news media requesting?
There are multiple methods by which the public requests data from State entities. For example, some PRA requests may seek to obtain data or records which are to be provided in digital format. These requests (particularly repeated requests for the same data) might be fulfilled by making the data available on an open data portal.
What data are different stakeholder groups interested in?
Consider engaging with the public for feedback through existing channels for public engagement and community feedback. Connecting with citizens and developers helps ensure that data releases are what stakeholders actually need. In addition, an open data portal could provide a mechanism for constituents to request data not yet published.
What data are frequently accessed on the organization’s website?
Website analytics and trends analysis will determine frequently accessed data.
What data have not been previously published but meet the definition of “high value”?
Publishable State data that can be used to increase organizational effectiveness and responsiveness, improve public knowledge of the organization and its operations, further the mission of the organization, create economic opportunity, or respond to a need or demand identified after public consultation.
Do data further the core mission or strategic direction of State entities?
Publishing aggregated data (statistics, metrics, performance indicators) as well as source data can often help an organization advance its strategic mission. In addition, an open data portal could serve as a conduit for efficiently sharing information with other organizations.
Do the data highlight an organization’s performance, or might publication of the data benefit the public by setting higher standards?
The organization might be in the forefront of standards for government performance, where exposing the data might encourage other State entities to raise their performance.
Does availability of the data align with federal initiatives or release of federal data?
There may be higher value in the organization’s data if synergies exist with federal data efforts.
Do the data support decision-making at the state, local, internal or other external entity level, or contain information that informs public policy?
Publishing such data publicly can be a powerful method for fostering productive civic engagement and policy debate.
Does availability of the data align with legal requirements for data publication?
There may be statutorily required reporting that can be satisfied by publishing data on an open data portal. If the data are collected and compiled by an organization to fulfill statutory reporting requirements, then that entity’s governing laws have already determined that the data are of high value.
Would availability of the data improve intra-State organization communication?
Certain government functions may involve multiple State organizations requiring access to similar data. Making the data available on an open data portal would support administrative simplification and efficiency.
Could availability of the data create specific economic opportunity?
In many cases, this will be unknown to the organization in advance. Some of the greatest successes of the open data movement have involved government data, such as weather data and other satellite imagery, being commercially appropriated in useful ways. To the extent an organization can anticipate significant commercial use of the data, they may wish to prioritize the publication of that data.
Could the data be used for the creation of novel and useful third-party applications, mobile applications, and services?
Software applications often leverage data from multiple sources to provide value to their customers. Making state data available can support the delivery of greater value (and impact) through those applications.
Are the data needed by the public after-hours?
Generally when there is demand outside normal business hours (that is known and quantifiable), such data should be ranked, where applicable, as high value.
Do the data have a direct impact on the public?
The data are likely of higher value if it is already apparent that there is a deep impact and interest by the public (e.g., public safety inspection results).
Are the data of timely interest?
Announcements of progress or success – or reactions to public criticism – can be strongly supported by publishing related data, should it exist.
Assessment Section B
Do the data tables represent discrete, usable information?
In identifying data tables, organizations may be concerned that users of an open data portal will not understand their data or, if distilled to its most raw form, the data may lose utility. There are no hard and fast rules about what level of detail is sufficiently granular to add value to a government data table. Whenever possible, organizations should resist the temptation to limit data to only those that they believe might be understood or useful. Entities should be wary of underestimating the users of an open data portal. Open data portal users may come from a variety of fields and specialties, who can envision a use for the data not anticipated by the organization. A better practice (as described in the section on Pre-Publication below) is for organizations to ensure that the metadata associated with each data table is complete, including comprehensive overview documents describing the data, uniform data collection, data fields, and the suggestion of potential research questions to maximize the usefulness of the data.
Prioritization

When creating a schedule for publication of a particular data table, organizations must make an assessment based upon a number of factors. Organizations should use the general guidance below (in conjunction with the Data Prioritization Survey) to determine the priority for each data table. Prioritizing initial and ongoing publication will entail balancing high value data with the data’s level of readiness for publication. Each organization should create and provide schedules prioritizing data publication in accordance with the guidelines set forth herein.
Prioritization done in a timely manner is important, recognizing that it may take time to prepare high quality data (noting that data tables vary in complexity and, as such, can significantly vary in preparation time). Approvals for the prioritization plan and scheduling will come from the organization’s executive leadership team.
In prioritizing data for release organizations must account for time to:
- Identify data
- Assess and validate data (i.e., ensure consistency, timeliness, relevance, completeness, and accuracy of the data)
- Ensure completeness of metadata and data dictionary
- Prepare visualizations and talking points
- Obtain all necessary approvals to publish data
3. Pre-Publication
Prior to publishing a data table on an open data portal, a number of steps first should be completed to ensure a high quality and usable product.
- Data tables should be formatted in a machine-readable format. Comma Separated Values (CSV) are the standard format for publication.
- Metadata (with adherence to the metadata guidelines – see below) and a data dictionary that provides descriptions and technical notes as necessary for each data table field should be compiled beforehand and submitted at the time of publication.
- Organizations are also encouraged to include with each data table one or more visualizations of the data (graphs and/or maps) as well as one or more potential research questions of interest as a way to encourage public engagement and innovation related to strategic goals.
- Each data table, as a part of the approval process, should be reviewed for quality assurance, compliance with the CHHS Data De-Identification Guidelines, and consistency of the data over time.
4. Publication
The publication process is meant to meet the publication guidelines of organizations. Considerations include branding, usability, design, and accessibility (e.g. Americans with Disabilities Act compliance). Each data table published on an open data portal requires appropriate categorization and tags (keywords) to provide ease in searching for the data. Furthermore, organizations may consider sharing the dataset’s publication via social media, a press release or other communication method.
Standardization
The way data consumers interact with and use an open data portal is greatly influenced by the way the data are published. Publishing contributors should provide data in a machine-readable format (CSV) to enable software tools, applications and systems to process it. However, there are many different types of standardization that can be found within an open data portal including: metadata, data dictionary, file naming conventions, demographic categories, and navigational categories and tags. Wherever possible, standards and associated guidelines should be developed to ensure consistency and facilitate automation and reuse of the data.
Metadata
Metadata is structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource (NISO 2004, ISBN: 1-880124-62-9). The standardization of a metadata schema and definitions allows for uniform access to fundamental information about an information resource. This also creates a structured environment allowing for consistent and reproducible searching, publishing and harvesting in a manner irrespective of the platform being used.
Open data portal should adhere to well used metadata standards such as the federal Project Open Data’s (POD) metadata schema standards. The POD metadata schema structure in turn is based upon the Data Catalog Vocabulary (DCAT) standard. In adopting these standards, open data portal can help facilitate interoperability between web based data catalogs and ensuring that federation between government entities is as seamless as possible.
Metadata shall also include information about origin, linked data, geographic location, time series continuations, data quality, and other relevant indices that reveal relationships between datasets and allow the public to determine the fitness of the data source. Machine readable formats for metadata should be prioritized.
Data Dictionary
While metadata provides information about the data as a whole, a data dictionary provides information about the fields within a data table. Specifically it provides details such as the common English title for the field, the data types included (i.e., plain text, number, money, percent, date/time, location), as well as full descriptions of the values within the field. These descriptions can include the raw data source, calculation methods for calculated data, descriptions of categories used (i.e., an age group) or time zones for date/time related data. This information helps the end user identify if a data table contains useful information for their needs. Machine readable formats for data dictionaries should be prioritized.
Categories, Tags and Keywords
Open data portals support a model that allows data publishers to identify data as belonging to a broad category (e.g., health and human services, public safety, and education). Then, using a schema that includes both standardized and category-specific tags and keywords, an open data portal helps data consumers to search and retrieve data tables readily and uniformly.
Data Formats
While the default format for publishing data on most open data portals are Comma Separated Value (CSV), portals generally support many other file formats. CSV files are generally used to generate an API (queryable data service) on open data portals, but many times data cannot be published in this format. To provide publishers additional flexibility platforms allow for formats such as:
Tabular Data
- CSV – Comma Separated Values
- XLS – MS Excel file extension
- JSON – JavaScript Object Notation
- XML – Extensible Markup Language
- RDF – Resource Description Framework
- ODF – Open Document Format
- ODS – Open Document Store
- TSV – Tab Separated Values
Geographic Data
- Zipped Shapefile – A shapefile is actually a collection of several files with the same file name, but differing extensions. For the Open Data Portal, each shapefile should contain (at a minimum) the following files:
- SHP – defines the vertices of the shape
- DBF – defines the attribute table
- PRJ – defines the projection for the data
- SHX – shape indexing file, for efficient processing
- REST Map/Feature Services – Representational State Transfer
- KML – Keyhole Markup Language
- KMZ – Zipped Keyhole Markup Language
- GeoJSON – Geographic JavaScript Object Notation
Other Data
- HTML/URL – Hypertext Markup Language/Uniform Resource Locator
- DOC/DOCX – Microsoft Document
- TXT – Text
- JPG – Joint Photographic Experts Group
- PNG – Portable Network Graphics
- GIF – Graphics Interchange Format
- TIFF – Tagged Image File Format
- PDF – Portable Document Format
- ZIP – Compressed File
- ODT – Open Document
- BIN – Binary File
Updates to Published Data Tables
Data on the open data portals must be kept up-to-date. Specific guidance regarding updates should be addressed in technical and working documents as they are developed. Each organization should be responsible for updates to their data based on their internal data governance model. Periodic internal review is highly recommended. The posting frequency for updates is generally included in the metadata for each data table and indicates how often the data table will be refreshed (e.g., annually, monthly, daily).
Federation
Federation Guidelines
Open data portals can include data records from other open data portals as well as data that has been loaded directly. This is done through a process called Federation. Portals, such as Data.ca.gov, the California Health and Human Services portal and the California Natural Resources Agency portal, provide publicly available JSON files containing metadata for their entire catalogs.
These JSON files are loaded into the portal and new records are created. To the end user these new records are almost identical to locally loaded records.
A very important aspect of federation is that the data comes from the originating portal as a single authoritative source. This maintains a single source for the data no matter how many times it is federated and streamlines any management.
Federation Requirements
For other organizations interested in having their portals harvested by and having their records displayed on the organization’s portal there are a few requirements. At the technical level, the portal must provide a JSON or XML file of their catalog and that file must be compatible with the metadata requirements (see above). On the management level the organization should have a data governance structure in place (see the Governance section) and have buy-off on the federation from the executive level, legal council and any public relations officers.